Самые основные принципы работы поисковых систем
 В этом посте я вам расскажу принцип работы поисковых систем.
В этом посте я вам расскажу принцип работы поисковых систем.
Думаю, данная публикация будет полезна не только начинающим seo — оптимизаторам, но тем владельцам сайтов, которые уже имеют небольшой опыт в раскрутке своих проектов.
Почему я так считаю? Дело в том, что сейчас в интернете можно встретить достаточно большое количество блоггеров, которые, в принципе, знают какие-то правила оптимизации, они покупают ссылки, пишут оптимизированные статьи и т.д.
Но далеко не все они знают, по какому принципу работают все поисковые системы, что,как мне кажется очень сильно мешает им понять все тонкости раскрутки сайтов.
Хотя я считаю, что первое, что должен узнать начинающий seo-оптимизатор это то, как работают поисковые системы. И в этой статье я постараюсь максимально подробно об этом рассказать.
Естественно, я буду говорить только о самом принципе работы поисковиков, а все вопросы технического характера (работа алгоритма) затрагиваться не будут.
Потому как, во-первых, эти алгоритмы держатся в строгой тайне, и никто кроме самих разработчиков поисковых систем их не знает, а во-вторых, они (алгоритмы) постоянно меняются и если, даже кому-то удастся узнать, как все работает, через некоторое время (1−2 недели) эта информация уже будет не актуальной. Но обо всем по порядку. Итак, начтем!
Как работают поисковые системы?
Первое что вы должны понять так это то, что все поисковые системы являются так называемыми «индексирующими» поисковиками. То есть, они выполняют поиск исключительно по своей базе данных, которая строится специальной программой, называемой поисковым роботом (или как ее еще называют индексатор, паук, кроулер, бот, червяк).
Получается, когда человек только создал сайт, ему необходимо подождать некоторое время чтобы поисковый робот нашел его ресурс и загрузил к себе в индекс (базу данных) и только после этого сайт будет участвовать в поиске.
Так же каждая поисковая система предоставляет возможность пользователю добавить свой ресурс в очередь на индексацию в ручном режиме, используя для этого специальную форму добавления адресов.
Но главное не это, главное чтобы вы поняли, что когда пользователь вводит в поисковик какой-то запрос поисковая система ищет информацию исключительно по своей базе данных. То есть она не перелапатывает весь интернет, чтобы показать вам страницы с необходимой информацией, она работает в рамках своей базы данных. Это очень важно понимать.
Этот принцип работы поисковых систем дает возможность искать информацию практически мгновенно. Мало того, благодаря ему имеется возможность показать пользователю максимально качественный результат выдачи, за счет предварительной обработки и структурирования информации в индексе. Давайте более подробно об этом поговорим.
Смотрите, как все происходит, когда поисковый робот заходит на сайт он сразу же начинает разбивать его на некие составляющие.
Во-первых, выполняется выборка всех ссылок из документа и добавления их в очередь для дальнейшего «путешествия» робота по просторам интернета. После чего робот начинает обработку текста страницы, разбивая его на некие логические составляющие, которые еще называют пассажами.
То есть, что значит пассаж? Все очень просто. Пассаж — последовательность слов или одно слово, находящееся в рамках html тега или знака препинания.
К примеру, у нас есть текст: «сейчас я пишу для вас статью, которая поможет вам понять принцип работы поисковых систем». Так вот, слова: «сейчас я пишу для вас статью» — это будет первый пассаж, а следующий набор слов — «которая поможет вам понять принципы работы поисковых систем» — это уже второй пассаж.
Как видите, данные слова разбиваются на пассажи в зависимости от знаков препинания. Но здесь важно знать, что поисковый робот видит нашу страницу не так как обычный пользователь, он ее обрабатывает в виде html кода, то есть он ее видит так:
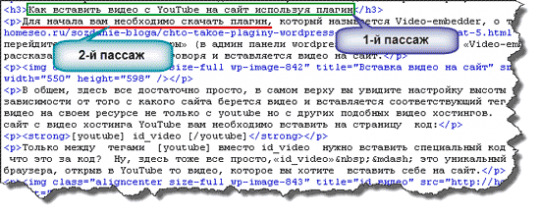
Причем в качестве разделителя пассажов выступают не только знаки препинания, но и теги блочных элементов (< p > ,< div >, < h1 > и т.д). Надеюсь здесь все понятно.
Идем, дальше.
После того как текс будет разбит на пассажи робот выполняет их структурирование по своей значимости. Дело в том, что вес того или иного текста на странице очень сильно зависит от того в каком html теге он находится.
К примеру, текст который находится в теге < h1 > будет иметь большую значимость для поисковой системы, нежели текст который заключен в тег < p >. Более точное распределение веса текста показано на рисунке:
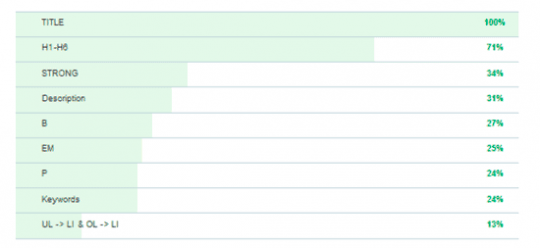
Конечно, вы должны понимать, что если вес текста в теге < h1 > больше, нежели в < p > это не значит что вы должны заключать весь текст в тег < h1 >, скорей всего этим вы себе только навредите.
Тем более это распределение значимости текста актуально только для ключевых слов. В общем, думаю, это понятно. Естественно, в будущем мы еще будем не раз говорить о том, как можно повысить вес страницы для поисковиков, так что подпишитесь на обновления блога, чтобы ничего не пропустить.
Помимо разбивки текста на пассажи робот выполняет расчленение текста и удаление так называемых «шумовых слов» или как еще их называют стоп слова.
Другими словами, робот удаляет из текста все предлоги и незначимые части речи, которые выражаются в таких словах: в, на, при, а, у, из, от. То есть это те слова, которые не несут смысловой нагрузки.
После того как все вышеописанные манипуляции будут выполнены поисковый робот помещает эти данные в основной индекс по которому и выполняется поиск информации.
Важно также знать, что помимо основного индекса поисковик сохраняет и копию страницы, которую он обработал. Эту копию вы можете очень легко посмотреть, нажать на ссылку «копия» которая обычно располагается возле результатов выдачи поисковой системы.

Когда вы перейдете по этой ссылке вы увидите копию страницы, которая на текущий момент находится в индексе поисковой системы. Если вы внимательно посмотрите, то увидите, что сверху страницу указывается время, когда поисковый робот индексировал данный документ.
Как по мне это очень важная опция, так как она позволяет узнать, когда в последний раз на ваш сайт заходил поисковый робот и какая копия страниц на данный момент находится индексе.

Исходя из вышесказанного, можно легко понять, что все производимые вами манипуляции на странице связанные с поисковой оптимизацией начнут действовать только через некоторое время, когда поисковик вновь зайдет на сайт и подхватит новую копию документа.
Кстати, если вы хотите узнать, сколько на данный момент находится страниц в индексе, можете воспользоваться очень простым запросом, который выглядит так: site:vash_domen.ru.
То есть вы просто вводите в строку поиску данный запрос (вместо vash_domen пишите свое имя домена) и смотрите, какие страницы участвуют в выдачи, выглядит это так:
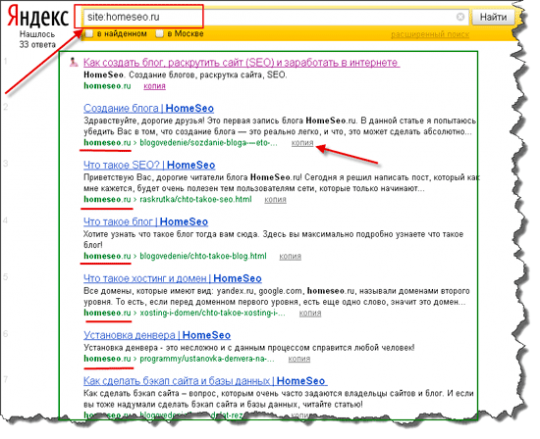
Как видите, в этом случаи поисковик показывает только те страницы, которые принадлежат конкретному сайту.
Внимание! Очень важно понимать, когда речь идет о поисковой выдачи или поисковой оптимизации имеется ввиду оптимизация отдельных страниц, а не сайта.
Запомните, для поисковых систем понятия сайта не существует!!! Когда пользователь вводит какой-то запрос в строку поиска, ему показываются страницы, а не сайты. То есть, оптимизируем мы именно отдельные страницы.
Может сейчас, вы не совсем понимаете, зачем я на этом делают такой акцент, но поверье друзья, знать это очень важно и в будущем я объясню почему, так что не забывайте время от времени заглядывать ко мне в гости 🙂 . Ну, да ладно, продолжаем.
Понятие ТИЦ, ВИЦ и PR
Помимо того что поисковик выполняет полную разбивку документа на пассажи и структурирование полученной информации для улучшения ее поиска, он также занимается оцениванием авторитетности обрабатываемой страницы.
Как это понять? Дело в том, что в каждой поисковой системе есть некий перечень факторов, которые она учитывает при определении полезности и авторитетности ресурсов.
Данных факторов существует очень много, но один из самых значимых — ссылочная масса. Другими словами это количество ссылок, которые ведут на страницу сайта. В просто народье этот фактор еще называют «индекс цитирования».
Такого рода оценивания качества информации пришло в интернет с научных кругов, именно там показатель ссылаемости на какую-то научную работу определяет ее качество.
Поисковые системы ввели условные показатели авторитетности сайта исходя из количества ссылаемых на него ресурсов. Для Google этот показатель называется PR (Page Rang), который измеряется от 0 до 10.
Для Яндекса это так называемый ТИЦ (тематический индекс цитирования), показывающий авторитетность сайта, этот показатель измеряется от 0 до условной бесконечности (у самого Яндекса ТИЦ300 000) .
Так же Яндекс ввел так называемый ВИЦ (взвешенный индекс цитирования), который определял вес ссылок ведущей на сайт.
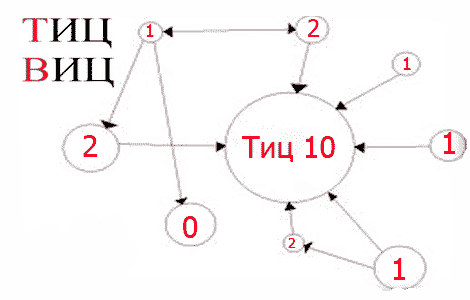
Получается, когда поисковый робот оценивает качество страницы, он берет в расчет количество ссылок ведущих на данную страницу, их вес и многие другие показатели. И это позволяет определить некий уровень качества индексируемой страницы, который учитывается при выдачи результатов пользователю вбившего в строку поиска кукую-то искомую фразу.
Естественно помимо вышеуказанных факторов поисковые машины берут в расчет и многие другие показатели, которые, как вы понимаются, держатся в строгой тайне.
Правда о некоторых из них стало известно посредством многих экспериментов и наблюдений специалистов в этой области, о них я вкратце рассказывал в этой статье, но, полного списка этих факторов никто не знает.
В общем, вы должны хорошо понимать, что поисковые машины — это очень сложный механизм, который выполняет огромную аналитическую работу для того чтобы оценить качество документа. Причем этот механизм постоянно совершенствуется и если можно так выразиться — эволюционирует.
Не зря сейчас существует много seo компаний, которые берут огромные деньги, за продвижение сайтов в ТОП выдачи поисковой системы, проводится колоссальная работа владельцами проектов в плане раскрутки своих ресурсов с целью получения прибыли.
И естественно, без знания базовых принципов работы поисковых систем здесь не обойтись.
Так же немаловажным является понимание того что поисковые машины вам ничего не должны и они имеют полное право удалить ваш сайт со своего индекса.
Особенно если вы нарушаете лицензию пользования поисковой системой, поэтому ни в коем случаи не пытайтесь каким-то образом «надуть» Яндекс или Google и повлиять на их выдачу, это может кончиться наложением на ваш ресурсов определенных санкций или же полным исключением его с поиска.
Конечно же, здесь имеется ввиду так называемы черные методы оптимизации, где используются специальные скрипты для перенаправления пользователя на другие сайты, скрытия контента от поисковых систем, массовая закупка ссылок, заспамленность страниц ключевыми словами и т.д.
Как бы там ни было вы должны хорошо осознавать, что ваш ресурс должен нести какую-то пользу посетителям. И если это будет так, то ни какие санкции поисковых систем вам не страшны. Это главное что нужно знать!
Вот и все что я хотел вам сегодня рассказать. Конечно же, в своих следующих публикация я буду более подробно останавливаться на таких понятиях как ТИЦ, PR, ВИЦ, поисковая оптимизация и т. д.
Поверьте, вас ждет еще много полезной информации, поэтому не забудьте подписаться на обновления.… А на сегодня у меня всё, желаю вам удачи и успехов в жизни!!!